
수정 했습니다.
Rev.1 | 초안 |
Rev.2 | Rev.2라고 적힌 부분 |
2. ownt_overwrite 추가 | |
|
|
후기 입니다.
이기환님처럼 잘 쓰지는 못할거 같지만....;;;
어쨌든 시작합니다~
이번 스터디는 크게 두가지를 하였습니다.
cache_clean_flush와 wont_overwrite 입니다.
이 두가지를 간단하게 살펴보도록 하겠습니다.
1. cache_clean_flush
1-1. __armv7_mmu_cache_flush 호출
/* Preserve offset to relocated code. */ sub r6, r9, r6 @@ 압축이 풀려있을 주소공간과 겹치고 있기 때문에 @@ zImage 를 위로 올리기 위해 offset 을 구한다. #ifndef CONFIG_ZBOOT_ROM /* cache_clean_flush may use the stack, so relocate it */ add sp, sp, r6 @@ stack 을 위로 올려준다 #endif bl cache_clean_flush @ code 의 주소가 달라졌으므로 cache 를 flush 해줘야 한다. adr r0, BSYM(restart) @ 바뀐 code(r6을 더함) 의 restart 의 주소를 r0 에 저장 add r0, r0, r6 mov pc, r0
호출 부분 입니다.
bl cache_clean_flush에서 flush를 진행 하도록 하죠.
그리고 다음과 같은 일을 하여 진행됩니다.
(해당 내용은 이미 자세히 알거 같아서 그림으로 대처합니다.)
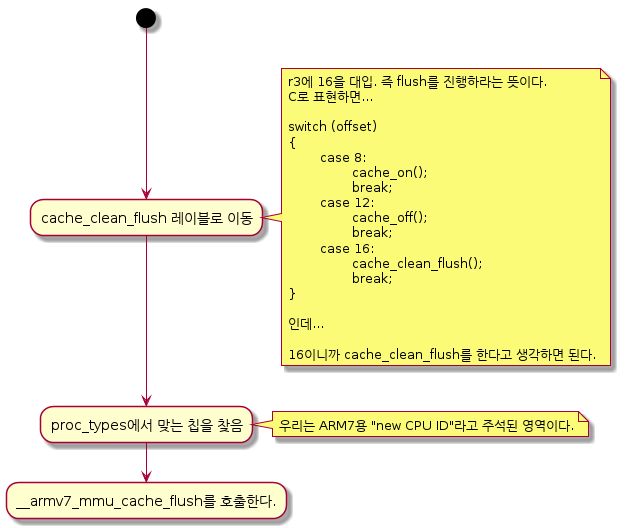
1-2. __arm7_mmu_cache_flush 진행
1-2-1. Hierarchical 인지 확인
__armv7_mmu_cache_flush: mrc p15, 0, r10, c0, c1, 5 @ read ID_MMFR1 tst r10, #0xf << 16 @ hierarchical cache (ARMv7) mov r10, #0 beq hierarchical mcr p15, 0, r10, c7, c14, 0 @ clean+invalidate D b iflush
ID_MMFR1을 r10에 얻어 와서 hierachical인지 확인하는 부분입니다.
hierachical이란건 다중으로 캐쉬가 있는걸 말하는거 같습니다.
L1, L2 캐쉬가 있다면 L1에 있는 내용을 모두 L2에 flush를 하고
그 이후에 L2에 있는 내용을 다시 메모리에 flush를 단계적으로 해야 하기 때문에
hierachical 인지 확인 하는 것이죠.
1-2-2. 캐쉬 총 개수 계산
hierarchical:
mcr p15, 0, r10, c7, c10, 5 @ DMB
stmfd sp!, {r0-r7, r9-r11}
mrc p15, 1, r0, c0, c0, 1 @ read clidr
ands r3, r0, #0x7000000 @ extract loc from clidr
@@ flush 해줘야 할 클린 레벨
mov r3, r3, lsr #23 @ left align loc bit field
@@ r3 = loc * 2
beq finished @ if loc is 0, then no need to clean
DMB를 하고
TODO: 이건 정확하게 무얼 하는 건지 알아봐야 한다.
clidr을 읽어 loc 영역에서 캐쉬의 최종 개수가 어떻게 되는지 알아 보는거 같아 보입니다.

ands r3, r0, #0x7000000을 하여 r3에 loc 영역만 남겨 놓고
mov r3, r3, lsr #23 을 하는데..
이 부분에서 봐야 하는건..
실제 loc는 24번째 비트에 있다는 것이죠..
23비트 만큼 우로 시프트를 하게 되면 0비트에 바로 붙지 않고 1비트에 붙는다는 것인데
이건 loc에 곱하기 2 한 효과가 있습니다..
이런게 이 후에 어떻게 사용될 것인가는 과제로 남기겠습니다.
1-2-3. 캐쉬에 대한 정보 얻기
mov r10, #0 @ start clean at cache level 0 loop1: add r2, r10, r10, lsr #1 @ work out 3x current cache level @@r2는 loop1을 돌때마다 3씩 증가 mov r1, r0, lsr r2 @ extract cache type bits from clidr and r1, r1, #7 @ mask of the bits for current cache only @@ +------+---------+ @@ |00 |no | @@ | |cache | @@ +------+---------+ @@ |01 |icache | @@ +------+---------+ @@ |10 |data | @@ | |cache | @@ +------+---------+ @@ |11 |I/D Cache| @@ +------+---------+ cmp r1, #2 @ see what cache we have at this level blt skip @ skip if no cache, or just i-cache mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr mcr p15, 0, r10, c7, c5, 4 @ isb to sych the new cssr&csidr mrc p15, 1, r1, c0, c0, 0 @ read the new csidr and r2, r1, #7 @ extract the length of the cache lines add r2, r2, #4 @ add 4 (line length offset) ldr r4, =0x3ff ands r4, r4, r1, lsr #3 @ find maximum number on the way size clz r5, r4 @ find bit position of way size increment ldr r7, =0x7fff ands r7, r7, r1, lsr #13 @ extract max number of the index size
r10에 0을 넣어 첫번째 캐쉬부터 캐쉬의 정보를 얻으려고 하는거죠.
후에 r10에 2씩 더하기를 해서 다음 캐쉬 정보를 얻게 하는데.
왜 2를 더하는지는....
이것 역시 수수께끼로 남겨 두겠습니다....^^;;;
(모르는데 이런 말씀을 드리는거 아닙니다!!ㅋㅋㅋ)
add r2, r10, r10, lsr #1 mov r1, r0, lsr r2 and r1, r1, #7
우선 위에 세 줄을 보면...
r1에 r10값에 1.5를 곱해서 clidr에서 필요한 Ctype 값을 넣는다. 가 최종 목적입니다.
이 말인 즉슥... r10이 0이면 그림의 Ctype1을 가져 와서 and 연산으로 나머지는 지우고..
r10이 2일 때(제가 2씩 증가 한다고 했죠~?) 1.5배를 하면 3이니까 3비트 부터 해서 Ctype2를 가져 와서 and 연산으로 나머지는 제거 하게 되죠.
r10이 4일 때 1.5배를 하면 6이니까 6비트 부터인 Ctype 3을 가져 오는거예요.
이렇게 캐쉬에 따라 필요한 Ctype을 r1에 넣습니다.
그럼 Ctype에는 뭐가 있는가??
해당 캐쉬가 icache인지 dcache인지 아니면 둘다인지.. 검사 하여서
icache이면 flush를 할 필요가 없으니(바뀐 내용이 있어야 flush를 할테니까요.^^)
그냥 skip 하게 됩니다.
그렇게 하는게 다음 소스였죠.
cmp r1, #2 blt skip
이 후에 캐쉬에 대한 내용을 csidr을 통해 얻어서 필요한 정보를 얻습니다.
여기서 얻는건..
LineSize, Associativity(Way 수), NumSets 을 각각 얻게 됩니다.
이 부분은 나머지 소스 영역입니다.
===Rev.2수정 시작{
위에 부분을 계속 읽다 보니.. 부족하다는 느낌이 너무 많이 들어서 조금 수정합니다.;;
일단 csidr에 대한 그림을 보면 아래와 같습니다.
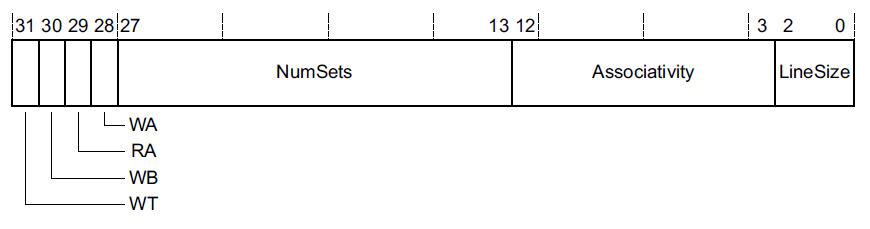
LineSize를 r2에 넣고 4를 더하게 됩니다.
4를 더하는 이유는 아래에 알려드리도록 하겠습니다.
그리고 r4와 r7에 각각 Associativity와 NumSets의 값을 넣는데..
여기서 주석을 보면 최대의 way와 최대 index 라는걸 알 수 있습니다.
후에 1씩을 빼면서 전체 way와 전체 index를 flush 하려고 하는 것죠.
그리고 처음 보는 명령어인 clz r5, r4 가 나옵니다.
이 clz r5, r4는 r4에 31비트부터 처음으로 1이 나오는 비트의 번째수를 구하는 겁니다.
예를 들어 r4에 b0000 0000 0000 0010 0000 0000 0000 0000 이라고 한다면...
1이 나오기 전에 빨간 0의 개수가 14개 있으니.. r5에는 14가 들어 갈 것입니다.
r5는 후에 way 부분을 앞으로 정렬(?) 하는 부분 때문에 필요한 레지스터 입니다.
}Rev.2수정 끝===
1-2-4. 해당 index에서 way 별로 flush
loop2: mov r9, r4 @ create working copy of max way size loop3: ARM( orr r11, r10, r9, lsl r5 ) @ factor way and cache number into r11 ARM( orr r11, r11, r7, lsl r2 ) @ factor index number into r11 @@ 메뉴얼 B.4.2.1 SET/WAY 레지스터 모양과 같은 형태를 만들어줌 mcr p15, 0, r11, c7, c14, 2 @ clean & invalidate by set/way @@ 웨이 안에 있는 한 라인 플러쉬 완료 subs r9, r9, #1 @ decrement the way bge loop3 @@ 현 웨이에서 - 1 웨이로 진입
여기서 알아야 하는건 크게 두개이다.
하나는 mcr p15, 0, r11, c7, c14, 2 를 할 때 레지스터의 구조이고
cache의 저장 정책인데...
일단 clean 할 때 구조를 보자.

입력할 때의 구조는 위와 같습니다.
여기서 필요한 way, set, level 등은 이전에 모두 계산 된 값들이죠.
이 값을 위의 형태로 채우기만 하면 됩니다.
아~~~주 간단하죠.^^
===Rev.2수정 시작{
아주 간단하다고 생각했는데...
어찌... 조금 복잡할 수 있겠다는 생각에 다시 수정 합니다..^^;;
way야 r4가 될 텐데...(r9에 r4를 넣긴 했습니다)
아까 제가 앞으로 정렬(?) 해야 한다고 했죠??
그래서 r5를 이용해서 시프트 연산을 하여서 orr를 하는 것입니다.
그 명령어가
orr r11, r10, r9, lsl r5
가 되겠죠..
그럼 r10은 먼가 하면... 캐쉬 레벨입니다.
지금은 0이니까 아무 값도 들어 가지 않겠지만..
후에 2가 되면(제가 2씩 증가 된다고 했었죠???ㅋ) 그럼 2가 입력되게 됩니다.
그런데 레벨은 0번째 비트 부터 입력되는게 하니라 1번째 비트 부터 입력되니까..
실제로 0번째 비트 부터 보시면... b0010 이라고 입력 되겠죠??
r10이 4가 되면... b0100 이 되고요..
어때요???
r10이 1씩 증가 되었다면 여기서 시프트 연산을 했어야 했는데
2씩 증가하니까 시프트 연산 없이 바로 입력 할 수 있게 되죠?? ^^;;
숙제로 내려 했는데.. 제가 답을 알려드렸네요..ㅋㅋ
그리고 이제 마지막 set부분인 index를 입력 해야 하는데..
이 때 사용하는게 orr r11, r11, r7, lsl r2 명령입니다.
r7이야 index고 r2는 LineSize라고 했었죠??
이제 LineSize에 왜 4를 더하는지 보이나요??? ^^;
Set부분은 LineSize에 따라 저장되는 위치가 다른데
시작 부분은 항상 Level을 입력하고 나서부터 입니다.
Level을 입력하는 부분은 총 4비트가 걸리니 그 이후에 Set을 입력해야 겠죠??
그러니 LineSize에 4를 더해서 Level 입력 부분 이후 부터 Set을 입력하라고 하는 겁니다.
}Rev.2수정 끝===
그리고 다음 명령어 부분을 보죠.
subs r9, r9, #1 @ decrement the way bge loop3
현재 way 값에서 하나의 값을 줄여서 다음 way를 flush 하는 거죠.
이 때 봐야 하는게 캐쉬의 정책인데요...
이건 민홍 교수님의 자료를 보도록 하겠습니다.
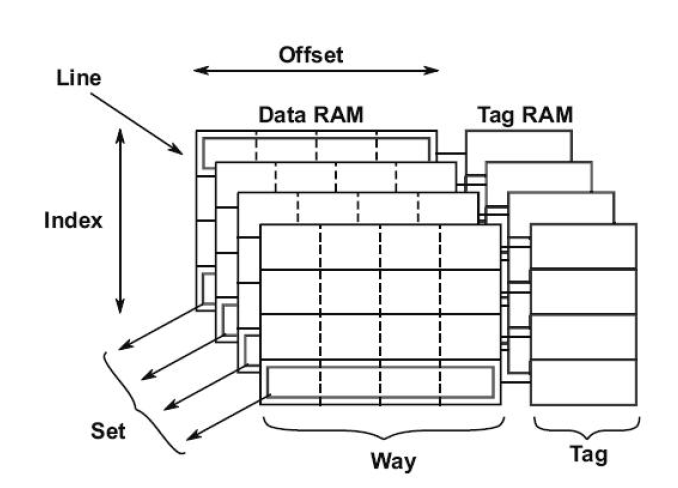
Way의 가장 큰 값이 가장 앞에 그려진 네모라고 보시면..
각 Way는 여러 index로 나눠지죠..
그림 상으로는 4개의 index겠네요.
처음 하게 되면 첫번 째 way에서 첫번째 index만 flush 하게 된거니..
way의 값을 하나 줄여서(그 뒤에 있는 way) 다음 way의 첫번째 index만 flush하는 거죠.
이렇게 반복을 해서 모든 way의 첫번째 index를 flush를 하면 됩니다.
1-2-5. 다음 index를 모두 flush 하고 다음 레벨의 캐쉬도 flush
subs r7, r7, #1 @ decrement the index @@ 현 인덱스에서 -1 인덱스로 진입 bge loop2 skip: add r10, r10, #2 @ increment cache number cmp r3, r10 bgt loop1 @@다음 레벨 캐시로 진입
당연히 위에서 첫번째 index만 flush를 했으니..
index 값을 줄이면서 다음 index들을 모두 flush 합니다.
이렇게 모든 way, index를 flush 하면 이제 다음 캐쉬로 넘어 갑니다.
1-2-6. 마무리
finished:
ldmfd sp!, {r0-r7, r9-r11}
mov r10, #0 @ swith back to cache level 0
mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr
iflush:
mcr p15, 0, r10, c7, c10, 4 @ DSB
mcr p15, 0, r10, c7, c5, 0 @ invalidate I+BTB
mcr p15, 0, r10, c7, c10, 4 @ DSB
mcr p15, 0, r10, c7, c5, 4 @ ISB
mov pc, lr
이 부분은 특별히 설명이 필요가 없을거 같네요.
마무리 하는거죠..
캐쉬를 모두 정리 하고 다시 return 하는 부분입니다.
2. wont_overwrite
압축을 풀 때 겹치는 부분이 없다면 해당 레이블로 들어 오게 됩니다.
사실 이 wont_overwrite는 크게 봐야 할 곳은 없는거 같습니다.
대충~~ 봐도 쉽게 이해 되는게 대부분일거예요..^^
그러니 쉽게 넘어 가도록 하겠습니다.
2-1. 이미지의 물리 주소와 실행 주소 차이 확인 후 보정
orrs r1, r0, r5 beq not_relocated add r11, r11, r0 @@파일 오프셋과 실제 메모리 주소상의 위치 차이 보정 add r12, r12, r0 #ifndef CONFIG_ZBOOT_ROM /* * If we're running fully PIC === CONFIG_ZBOOT_ROM = n, * we need to fix up pointers into the BSS region. * Note that the stack pointer has already been fixed up. */ add r2, r2, r0 @@BSS 주소도 위치 차이 보정 add r3, r3, r0 /* * Relocate all entries in the GOT table. * Bump bss entries to _edata + dtb size */ ;; @@재배열된 주소공간을 가르키는 GOT 엔트리 보정 1: ldr r1, [r11, #0] @ relocate entries in the GOT add r1, r1, r0 @ This fixes up C references cmp r1, r2 @ if entry >= bss_start && cmphs r3, r1 @ bss_end > entry addhi r1, r1, r5 @ entry += dtb size str r1, [r11], #4 @ next entry cmp r11, r12 blo 1b /* bump our bss pointers too */ add r2, r2, r5 add r3, r3, r5
r0 값(예~~~전에 .LC0로 실제 이미지의 메모리 주소와 수행 중 메모리 차이를 구했죠..)인
값을 이용해서 r0 만큼 차이를 보정 하는 부분입니다.
진짜!! 쉽습니다...!!
중간에 하나 신경 써야 하는 부분이 있다면...
cmp r1, r2 @ if entry >= bss_start &&
cmphs r3, r1 @ bss_end > entry
addhi r1, r1, r5 @ entry += dtb size
이 부분인데..
이건 처음에는 이미지의 끝과 bss 영역 사이에는 아무 것도 없었는데..
head.S를 진행 하다 보니 중간에 dtb가 추가 되었죠???
그러니 bss 영역을 dtb 위쪽에 배치를 해야 하니까 저 명령어 부분이 추가 된거 같습니다.
(이 부분 잘못된거 있으면 알려주세요.^^;;)
2-2. BSS 영역 초기화
not_relocated: mov r0, #0 1: str r0, [r2], #4 @ clear bss str r0, [r2], #4 str r0, [r2], #4 str r0, [r2], #4 cmp r2, r3 blo 1b
딱 봐도.. BSS 초기화 부분 같죠??? ^^;;
넘어 가겠습니다.
2-3. 압축 풀기
mov r0, r4 mov r1, sp @ malloc space above stack add r2, sp, #0x10000 @ 64k max mov r3, r7 bl decompress_kernel @@ 함수 호출
최종 목적은 decompress_kernel을 호출 하기 위한건데..
ABI에 따라 각 레지스터에 필요한 파라미터를 넣고 있습니다.
r0, 1, 2, 3인 각각은 커널 실행 주소, stack의 시작, stack의 끝, architecture ID를 넣어서
함수를 호출 합니다.
해당 함수는... 별로 중요한게 없어서 넘어가겠습니다~~^^;;
2-4. 캐쉬 정리
bl cache_clean_flush // @@ 압축을 해제할때 cache 를 사용했으므로 cache flush 를 해준다. bl cache_off
압축을 풀 때 사용했던 cache를 모두 정리 하는 것입니다.
cache_off 부분은 너~~무 간단해서 넘어가도록 하겠습니다.^^;;;;;
(진짜!! 쉬우니 꼭 한번 보세요~~)
2-5. __enter_kernel 호출
mov r1, r7 @ restore architecture number mov r2, r8 @ restore atags pointer b __enter_kernel
__enter_kernel을 호출하기 위해서 r1과 r2에 필요한 값을 넣습니다.
여기서 r0은 어떤걸 입력하는건가?? 라는 질문이 나왔는데...
그건 다음 명령어를 보면 알 수 있습니다.
2-6. 압축 푼 커널의 시작 부분 호출
__enter_kernel:
mov r0, #0 @ must be 0
ARM( mov pc, r4 ) @ call kernel @@ kernel 의 시작 주소로 간다. arch/arm/kernel/head.S
여기서 r0를 입력하게 되는거죠..^^;
그리고 pc에 r4를 넣어서 압축을 푼 커널로 이동을 하는 거죠.
이렇게 토요일에 모든 내용을 정리(?) 하였습니다.
head.S를 끝내기 위해 막판 15분 동안 cache_off를 끝낸걸 보면 참 대단했다고 생각했습니다.^^
B팀은 먼저 드라이빙을 정리 하면서 어려운걸 알려주고...
C팀에서는 질문 거리를 정리 하고..
A팀은 주석 보다 조금 더 자세하게 정리하고..
먼가.. 이 세팀이 스타일이 모두 달라서 서로 시너지 효과를 얻고 있는 듯한 느낌입니다.
앞으로도~~ 모든 팀들이 서로 힘을 합쳐서 어느 팀도 낙오 하지 말고 모두 목표한 바를 얻었으면 좋겠습니다~^^
댓글 21
-
HyunGyu
2013.08.04 21:09
-
K
2013.08.05 13:13
기다리던 후기가 올라왔군요~~ ^^
정독하기 전에 고마움의 표시를 먼저 해야 겠습니다.
현규완님, 감사해요~
질문은 정독 후에... ㅋ
-
K
2013.08.05 19:50
저도 그랬었어요.. ㅋㅋㅋ
'이러다가 머릿속에 정리내용이 다 들어가는거 아닐까?' 하는 묘한 기분도 들었었죠.. ㅋㅋ
자기가 쓴 글을 읽고 또읽고 하는 건, 아마도 트리플 에이형 개발자들의 공통적인 습성이 아닐까.. 하는 생각이 드네요. ㅠㅠ
일단 한번 적은 건 누군가가 지적해줄때까지 방치하는 미덕도 필요합니다. ^^;;
그렇게 하시죠~
곧 지적하러 갈께요.. -
HyunGyu
2013.08.05 18:24
제가 후기를 적고.. 아마 제가 제일 많이 읽었을거 같네요..;;
읽을 때마다 부족한게 보여서..
얼른 수정 하고 싶은데..
빨리 퇴근 해버리고 싶은데..
이번 주는 꽤나 늦게 퇴근을 하게 될거 같아 걱정입니다. ㅠㅠ
-
정용복
2013.08.05 17:12
깔끔한 후기 감사합니다.~ 무엇보다 Head.s가 끝났다는 것에 대해 속이 후련합니다. ^___^
-
K
2013.08.05 19:53
31868 7월 28 01:18 ./arch/arm/boot/compressed/head.S16330 7월 28 01:18 ./arch/arm/kernel/head.S새로운 head.S는 사이즈가 절반이네요.. ^^ -
HyunGyu
2013.08.05 18:22
저도 그게 가장 즐거운 일이라 생각합니다~ㅋㅋ
근데 또 다른 head.S가 기다리고 있다는 사실을 알게 되었네요..ㅋㅋ
다음 주는 새로운 마음으로 새로운 head.S를 시작 하면 되겠죠~^^
-
김건용
2013.08.05 17:41
감사합니다.
-
HyunGyu
2013.08.05 18:21
이제 반 썼는걸요~
이번주는 회사 일이 많은거 같아서...
언제쯤 마무리를 할 수 있을지 저도 궁금합니다..^^;;;;;
-
신동석
2013.08.06 15:06
후기 잘 봤습니다..정리 깔끔하게 잘 하시네요..
제가 궁금한 부분은 압축 해제 할 때 여러 소스를 경유해서..
최종적으로 lib/decompress_inflate.c의 STATIC int INIT gunzip() 함수를 호출하는데..
int와 함수명 사이의 INIT이라는 지시자가 무엇을 의미하냐 입니다..
다 아시는 거 같아서 질문을 못했었는데 전 처음 보는 거라서요..^^;;
혹시 아시는 분 있으면 알려주세요~
-
HyunGyu
2013.08.06 19:35
오히려 질문이 저에게는 큰 감사함을 느낌니다.^^
복습 열심히 하세요~
-
신동석
2013.08.06 17:38
아 #define으로 정의 되어 있는거군요..전 제가 모르는 C언어 문법이 있나 해서 한참 찾았네요..
답변 감사합니다..
-
K
2013.08.08 12:35
저도 관심이 가서 찾아보았습니다.
아래 링크가 좀 더 디테일한 버전인 것 같군요..
어떤 원리로 __init이 붙은 영역이 추후 재사용 가능하게 되는지에 대한 설명까지 있어요.
http://venkateshabbarapu.blogspot.kr/2012/09/init-call-mechanism-in-linux-kernel.html
-
HyunGyu
2013.08.06 16:14
정확한 답변이 안될 수 있지만...
일단 간단하게 찾아본 내용을 알려드릴게요~
일단 동일 파일에서 INIT에 대한 define은..
#define INIT
으로 되어 있어서..
아무 것도 없는걸로 볼 수 있습니다.
그럼 어떻게 define 될 수 있을까요??
그래서 조금 찾아 봤는데..
__init이 아닐까 하네요..
#define INIT __init
이렇게요~
(include/linux/decompress/mm.h 에 define이 정의 되어 있습니다.
이 파일이 decompress_inflate가 include를 할지 어떨지는 모르겟지만요..^^;;)
그럼 __init에 대해서 조금 알아 봤는데..
여길 보시면 쉽게 이해가 가길겁니다.
뭐.. 링크를 가기 귀찮다면..
부팅 시점에 한번만 호출 될거 같은 함수 앞에 __init을 붙이면 메모리가 해당 영역을 사용할 수 있다?? 정도 일거 같아요.^^;
정확하지 않으니..
다시 한번 찾아 보시는것도 좋을거 같습니다~
-
오규승
2013.08.06 19:57
후기 읽기전에 감사 말씀 먼저 드립니다.
스터디에 참여하면서 느끼는거지만 아무런 대가도 없는 활동에 추가로 개인시간까지 할애하기가 정말 쉽지 않은데
활동하시는 열정이 정말 부럽고 기여하는것 없이 항상 얻어만 가는 제 자신이 부끄러워집니다.ㅠㅠ
후기 올려주신 현규완님을 더불어 스터디를 위해 헌신하시는 분들께 다시 한번 감사드립니다.
-
K
2013.08.08 12:41
이번주 예상외로 바빠서.. 짬짬이 조금씩 읽고 있는데.. 어렵군요.. ㅠㅠ
역시 본 수업을 빠지면 안되나봅니다.
위에 현규완님께서도 TODO로 달아놓으셨지만, DMB/DSB/ISB가 각각 무엇이고 왜 하는지가 궁금합니다.
혹시 스터디시간에 나온 얘기가 있었나요?
-
myskan
2013.08.08 17:27
DMB - data memory barrier operation
DSB - data synchronization barrier operation
ISB - Instruction synchronization barrier operation
-
K
2013.08.13 15:03
제가 너무 편협하게 보고있었나 봅니다.저는 head.S의 코드만 생각을 했었는데... ^^;;혹시 이렇게 생각하면 될까요?1. 비순차 실행 환경이라면 명령어 스케줄링으로 인해 프로그램의 작성된 순서와는 다른 순서로 실행될 수 있다.2. 하지만 다른 순서로 실행된 명령 결과들은 리오더 버퍼에서 대기하다가 프로그램의 작성된 순서에 맞춰 커밋되어야 한다.이런 환경에서 캐시플러시 명령이 실행될 경우,해당 명령을 기준으로 이전의 모든 명령어들이 처리완료되어야 하며 (리오더버퍼에서 커밋?)캐시플러시에서 데이터캐시는 모두 clean&flush 하고, 명령어캐시는 invalidate 한다.따라서 캐시플러시 이후의 모든 명령어들은 메모리에서 새로 읽어와야 한다.그리고, DMB/DSB/ISB 각 명령어의 내부 동작을 이런 식으로 생각해도 되는걸까요?1. DMB : DMB 이후의 명시적인 메모리 액세스를 시작하기 전에, DMB 이전의 모든 명시적인 메모리 액세스를 완료하도록 한다.--> 명령어 스케줄링시에, DMB 이후의 메모리 액세스가 먼저 준비되었더라도 DMB 이전의 모든 메모리 액세스가 완료될 때 까지 대기하도록 하는 명령2. DSB : DSB 이전의 모든 명령들을 완료하도록 한다.--> 명령어 스케줄링시에, DMB 이후에 위치한 명령어들이 준비되었더라도 대기시키고 DMB 이전의 명령들이 완료될 때 까지 대기하도록 하는 명령3. ISB : 파이프라인을 비워서, ISB 이후의 모든 명령들이 캐시나 메모리로부터 새로 펫치되도록 한다.--> 파이프라인을 모두 비운다. 이때 스케줄링 대기중이던 Reservation Station도 모두 비운다.myskan 님이 아니더라도 조언을 주시거나 함께 토론을 할 수 있으면 좋겠습니다. ^^ -
myskan
2013.08.11 15:50
캐시 flush에 대한 해당 코드 말고...
그 이전에 어떤 동작들이 수행될지 생각해 보세요.
캐시 flush는 현재 분석하시는 곳에서만 호출 되는 것이 아닙니다.
-
K
2013.08.09 03:55
힌트 주셔서 고맙습니다. ^^
좀 찾아보았는데요, 아래 링크에서 각 명령어 정의를 보면..
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.faqs/ka14041.html
DMB : DMB 이후의 명시적인 메모리 액세스를 시작하기 전에, DMB 이전의 모든 명시적인 메모리 액세스를 완료하도록 한다.
DSB : DSB 이전의 모든 명령들을 완료하도록 한다.
ISB : 파이프라인을 비워서, ISB 이후의 모든 명령들이 캐시나 메모리로부터 새로 펫치되도록 한다.
이 내용을 토대로 arch/arm/boot/compressed/head.S의 아래 코드들에서 각 명령의 용도를 설명해보면, (소설입니다. 아직 소스코드의 이해도가 높지 않은 관계로 ㅠㅠ)
hierarchical cache를 loop 돌면서 flush 해주기 위해 레지스터들을 사용할 예정이므로, r0-r7, r9-r11을 stack에 push 한다.
이때 stack에 push하는 '명시적인 메모리 액세스' 시작전에, 이전의 모든 명시적 메모리 액세스를 완료하도록 한다. (9번라인 DMB의 역할)
그런데 아래 코드에서는 DMB 이전에 처리되어야 할 명시적 메모리 액세스 작업은 없다.. 고 봐도 될까요?
__armv7_mmu_cache_flush: mrc p15, 0, r10, c0, c1, 5 @ read ID_MMFR1 tst r10, #0xf << 16 @ hierarchical cache (ARMv7) mov r10, #0 beq hierarchical mcr p15, 0, r10, c7, c14, 0 @ clean+invalidate D b iflush hierarchical: mcr p15, 0, r10, c7, c10, 5 @ DMB stmfd sp!, {r0-r7, r9-r11} mrc p15, 1, r0, c0, c0, 1 @ read clidr ands r3, r0, #0x7000000 @ extract loc from clidr mov r3, r3, lsr #23 @ left align loc bit field beq finished @ if loc is 0, then no need to clean mov r10, #0 @ start clean at cache level 0mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr
위 명령을 실행하고나서 아래 명령은 이미 파이프라인에 들어있는것이 아니라 캐시나 메모리로부터 새로 읽어와야한다. (8번라인 ISB의 역할)
mrc p15, 1, r1, c0, c0, 0 @ read the new csidr
여기에서, 왜 이미 파이프라인에 들어있는 명령을 그대로 사용하면 안되는지가 잘 이해가 안가네요..
ARM infocenter의 예제에서는 ISB의 경우 Memory Remapping 혹은 Self-modifying code에서 사용하는것 같은데, 지금의 코드는 그런 케이스는 아닌 것 같아서요..
loop1: add r2, r10, r10, lsr #1 @ work out 3x current cache level mov r1, r0, lsr r2 @ extract cache type bits from clidr and r1, r1, #7 @ mask of the bits for current cache only cmp r1, #2 @ see what cache we have at this level blt skip @ skip if no cache, or just i-cache mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr mcr p15, 0, r10, c7, c5, 4 @ isb to sych the new cssr&csidr mrc p15, 1, r1, c0, c0, 0 @ read the new csidr and r2, r1, #7 @ extract the length of the cache lines add r2, r2, #4 @ add 4 (line length offset) ldr r4, =0x3ff ands r4, r4, r1, lsr #3 @ find maximum number on the way size clz r5, r4 @ find bit position of way size increment ldr r7, =0x7fff ands r7, r7, r1, lsr #13 @ extract max number of the index size
mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr
위 명령을 완료한 이후에 아래의 명령을 실행하겠다. (6번라인 DSB의 역할)
mcr p15, 0, r10, c7, c5, 0 @ invalidate I+BTB
그리고 invalidate I+BTB 명령이 완료되기를 기다렸다가.. (8번라인 DSB의 역할)
파이프라인을 비우고 mov pc, lr 명령을 새로 읽어오겠다. (9번라인 ISB의 역할)
finished: ldmfd sp!, {r0-r7, r9-r11} mov r10, #0 @ swith back to cache level 0 mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr iflush: mcr p15, 0, r10, c7, c10, 4 @ DSB mcr p15, 0, r10, c7, c5, 0 @ invalidate I+BTB mcr p15, 0, r10, c7, c10, 4 @ DSB mcr p15, 0, r10, c7, c5, 4 @ ISB mov pc, lr
이렇게 이해하면 되는건가요?(흠.. 혼자 버벅거리고 있는 중.. ㅠㅠ)
틀린 부분 있으면 지적 부탁드립니다.~
-
아폴로
2013.08.12 11:11
수고하셨습니다. 도움을 많이 받고 있습니다...^^
.

이상한거 궁금한거 모두 질문 받을게요!!
모르는거 그냥 넘어가지 마세요~~^^
그리고 잘못된거 알려주시면 수정도 하겠습니다.