
[커널 18차] 2주차
2021.06.05 22:21
참석
-
xx명 참석
-
강혁+, 권경환, 권대엽, 권효만+, 금승원+, 김각래+, 김경인+, 김동훈, 김민경+, 김성원+, 김성준+, 김승현+, 김원우+, 김은영, 김정임+, 김준영+, 김지태, 김태완, 김택우+, 김한구, 김현우+, 김형종, 류호은, 문연수+, 문호찬, 문희찬+, 민호기+, 박노은+, 박상호, 박소연, 박시현, 박청수, 박현진, 봉하승, 서민혁, 송기원, 송준영+, 신보현, 신현종, 안성원+, 안유빈, 안이수, 원민수, 위대한, 유민호, 유원상, 유재홍, 유준환, 이민욱, 이윤성, 이일영, 이재욱, 이재훈+, 이정민, 이정아, 이정재+, 이주형, 이준후, 이한솔, 이형래, 이훈종, 임채훈, 정동훈, 정은식, 정주희, 조기석, 조만재, 조안나, 조현철, 지영근, 차민희, 천승환, 최서정, 최연욱, 최영민+, 최준근+, 한윤재, 황바른, 황성민+, 황성연
진도 및 내용
서기 : 김현우, 김성원
공유 : 이민욱
진도 : 81p
-
쓰레드간 공유되는 영역
-
data, text, heap
-
공유되지 않는 영역
-
stack, thread local storage
-
Thread Local Storage (TLS) 장점
-
커널의 percpu(cpu별로 동작)와 비슷한 개념, tls (쓰레드 별로 동작)
-
보안 문제, 전역변수 -> 모든 쓰레드가 공유, 공유하면 안되는 것들
-
성능 문제, 캐시핑퐁 (자세한 건 나중에)
-
거짓공유? 주변의 메모리까지 같이 이동되는거?를 방지
-
cpu는 cpu끼리 thread는 thread끼리 묶으면 성능개선 (cacheline)
-
stack에 위치하는 건 아니고 별도의 공간에 위치
-
fork vs vfork
-
fork 무겁다, vfork 가볍다 (옛날얘기)
-
fork는 COW를 하고 vfork는 안한다
-
vfork는 부모 프로세스의 페이지테이블을 복사하지 않는다
-
사본 (페이지테이블 따로 필요) vs 공유, vfork는 사본을 최대한 줄임
-
차이를 점점 없애는 추세
-
COW에서 페이지 테이블을 복사할 때 R/W속성이 바뀌는지는 나중에 확인
https://en.wikipedia.org/wiki/Copy-on-write
Copy-on-write는 특정 메모리 페이지를 읽기 전용으로 표시하고 페이지에 대한 참조 수를 유지함으로써 페이지 테이블을 사용하여 효율적으로 구현할 수 있습니다. 이러한 페이지에 데이터가 기록 될 때 커널은 쓰기 시도를 가로 채고 하나의 참조 만있는 경우 할당을 건너 뛸 수 있지만 쓰기시 복사 데이터로 초기화 된 새 물리적 페이지를 할당합니다. 그런 다음 커널은 새 (쓰기 가능) 페이지로 페이지 테이블을 업데이트하고 참조 수를 줄이고 쓰기를 수행합니다. 새로운 할당은 한 프로세스의 메모리 변경이 다른 프로세스에서 보이지 않도록합니다.
-
parent/child process를 구분하지 않고 몇 개의 프로세스에서 메모리를 참조하고 있나가 중요한 것 같습니다. 참조하는 프로세스가 자기 하나 뿐이면 COW 없이 바로 write를 하고 참조하고 있는 프로세스가 자기 이외의 다른 프로세스가 있다면 COW를 하게 되는 것 같습니다.
-
fork vs exec
-
exec pid 새로 안만든다
-
exec는 복귀를 하지 않는다
-
vfork는 복귀를 한다 (pid 당연히 새로 만듬)
-
동적할당한거 아마 해제하고 exec해야할 거 같다
-
system vs exec
-
최근 커널에서 do_fork -> kernel_clone 으로 네이밍이 바뀌었다.
-
tgid는 'task_struct→tgid'. 이를 출력하는 유저 함수는 getpid() , 커널 함수는 task_tgid_nr()
-
pid는 'task_struct→pid'. 이를 출력하는 유저 함수는 gettid(), 커널 함수는 task_pid_nr()
gettid()??
#include <stdio.h>
#include <unistd.h>
#include <linux/unistd.h>
int main()
{
pid_t pid = 0;
pid_t tid = 0;
pid = getpid();
// ‘__USE_GNU’ in musl
// gettid() 가능
tid = syscall(__NR_gettid);
printf("pid=%d, ttid=%d\n", pid, tid);
}
-
Q: clone 또는 fork시에 페이지 테이블을 어떻게 복사하는지?
A: 아래와 같은 경로를 타고 동작하며 페이지 테이블을 복제하고, 부모 페이지 중 COW 페이지들의 매핑 엔트리는 자식 페이지 테이블에 복사할 때 Read-only로 프로텍션을 변경하여 매핑합니다.
clone & fork의 경우 VM_CLONE 플래그 없이 kernel_clone()을 호출합니다.
-> sys_clone() -> kernel_clone() -> copy_process() -> copy_mm() -> dup_mm()
dup_mm()이 하는 일
=============================
1) 부모 mm_struct 복사
2) mm_init() -> mm_alloc_pgd() : mm->pgd에 pgd_alloc()으로 할당한 새 페이지 테이블 연결
3) dup_mmap() -> vm_area_dup() : 부모 mm->mmap에 연결된 vma들 복사, pgd 테이블 엔트리들도 복사, cow(no-shared+write) 페이지인 경우 read-only로 변경
최신 커널의 태스크 상태 전이 블럭 다이어그램(task state transition block diagram)

ARM32 기준 (arch/arm/include/asm/ptrace.h)
struct pt_regs {
unsigned long uregs[18];
};
ARM64 기준 (arch/arm64/include/asm/ptrace.h)
struct pt_regs {
union {
struct user_pt_regs user_regs;
struct {
u64 regs[31];
};
};
#ifdef __AARCH64EB__
#else
#endif
u64 unused; // maintain 16 byte alignment
u64 stackframe[2];
};
-
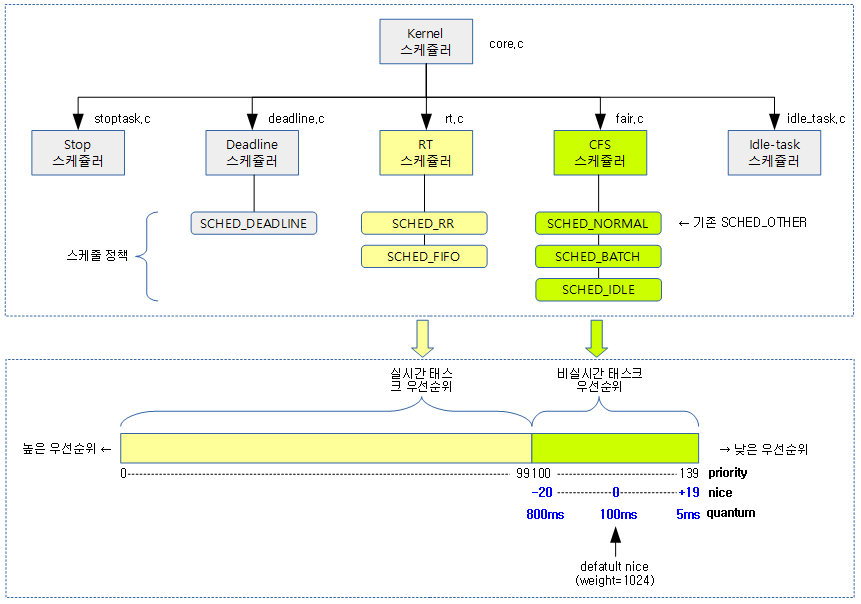
priority 140단계는 nice 40단계 + real-time 100단계
(include/linux/sched/prio.h)
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)
(=40)
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
(=100)
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
(=140)
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
(=120)
-
Main 쓰레드 스케줄러 바꾸는법
struct sched_param main_param
sched_getparam(getpid(), main_param);
// 우선순위 바꿀려면 다음 코드 실행
// main_param.sched_priority = 원하는 우선순위값
// 예를들어 SCHED_FIFO로 변경한다면
sched_setscheduler(getpid(), SCHED_FIFO, &main_param);
-
자식 쓰레드 스케줄러 바꾸는법
pthread_attr_t sched_attr;
pthread_attr_init(&sched_attr);
// 부모 쓰레드와는 다른 스케줄링을 사용하겠다고 선언
pthread_attr_setinheritsched(&sched_attr, PTHREAD_EXPLICIT_SCHED);
// 예를들어 SCHED_FIFO로 변경한다면
pthread_attr_setschedpolicy(&sched_attr, SCHED_FIFO);
-
쓰레드 스케줄링할 cpu 지정하는법
cpu_set_t cpuset;
CPU_SET(1, &cpuset); // 1번 cpu
CPU_SET(2, &cpuset); // 2번 cpu
…
pthread_attr_setaffinity_np(&sched_attr, sizeof(cpu_set_t), &cpuset);
-
마이그레이션할때 캐시친화력이 높은 곳으로 먼저함
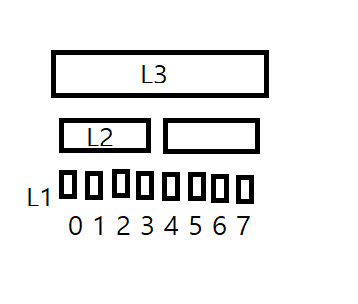
-
하이퍼스레딩 / 하드웨어스레드
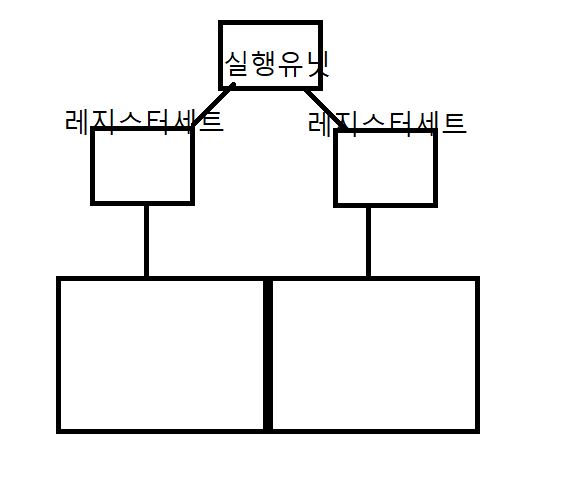
실행유닛: 파이프라인이라고 생각할 수 있음
대충 성능 10% 정도 올라가더라
shared mode vs adaptive mode
https://stackoverflow.com/questions/12249902/about-adaptive-mode-for-l1-cache-in-hyper-threading
-
RBtree -> 가장 deadline 빠른거 가져오는거 빠르다
커널스택, 유저스택 대응 관계 및 커널 스레드
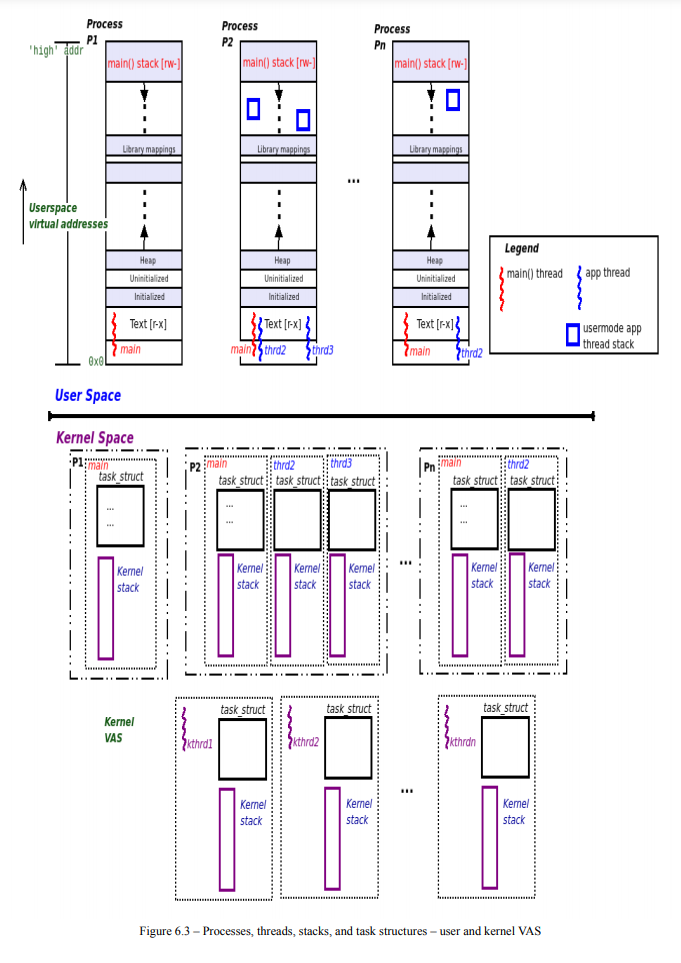
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 공지 | [공지] 스터디 정리 노트 공간입니다. | woos | 2016.05.14 | 627 |
| 68 | [커널 17차] 41주차 | ㅇㅇㅇ | 2021.06.13 | 36545 |
| 67 | [커널 18차] 3주차 | V4bel | 2021.06.12 | 103 |
| 66 | [커널 17차] 40주차 | ㅇㅇㅇ | 2021.06.05 | 283 |
| » | [커널 18차] 2주차 | V4bel | 2021.06.05 | 271 |
| 64 | [커널 17차] 39주차 | ㅇㅇㅇ | 2021.05.29 | 184 |
| 63 | [커널 18차] 1주차 | V4bel | 2021.05.29 | 3599 |
| 62 | [커널 17차] 38주차 | ㅇㅇㅇ | 2021.05.23 | 366 |
| 61 | [커널 17차] 37주차 | ㅇㅇㅇ | 2021.05.16 | 97 |
| 60 | [커널 17차] 36주차 [2] | ㅇㅇㅇ | 2021.05.09 | 133 |
| 59 | [커널 17차] 35주차 | ㅇㅇㅇ | 2021.05.05 | 85 |
| 58 | [커널 17차] 34주차 | ㅇㅇㅇ | 2021.04.25 | 99 |
| 57 | [커널 17차] 33주차 | ㅇㅇㅇ | 2021.04.18 | 195 |
| 56 | [커널 17차] 32주차 | ㅇㅇㅇ | 2021.04.11 | 443 |
| 55 | [커널 17차] 31주차 [2] | ㅇㅇㅇ | 2021.04.04 | 158 |
| 54 | [커널 17차] 30주차 [1] | 주영 | 2021.03.30 | 203 |
| 53 | [커널 17차] 29주차 | ㅇㅇㅇ | 2021.03.26 | 103 |
| 52 | [커널 17차] 27주차 | 주영 | 2021.03.15 | 276 |
| 51 | [커널 17차] 27주차 | 주영 | 2021.03.08 | 172 |
| 50 | [커널 17차] 26주차 | 주영 | 2021.03.01 | 539 |
| 49 | [커널 17차] 25주차 | 주영 | 2021.02.23 | 91 |
.
