
[커널 18차] 1주차
2021.05.29 22:21
참석
53명 참석
진도 및 내용
서기 : 김현우, 김성원
공유 : 이민욱
진도 : 10p ~ 54p 중간 (2주차 '만일 스레드 생성' 부터 시작)
(우선 순위 없는)라운드로빈이 초기 커널의 프로세스 스케쥴링 방식
디스크 최소 단위는 섹터(512 Bytes) -> 섹터가 모여서 Block
RM(Rate-Monotonic)정책 : 수행 주기가 가장 짧은 프로세스에 가장 높은 우선순위를 부여하는 방식
* 비율에 따라 우선순위가 단조롭게 증가하는 추세를 보인다고 하여 '비율 단조'라는 이름이 붙게 되었다.

RM을 쓰는 이유: RM LUB (Rate Monotonic Least Upper Bound)
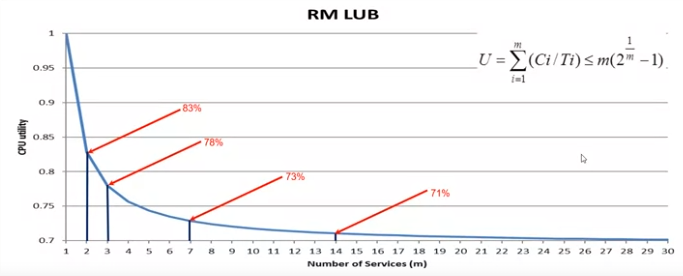
우선, RM은 Real-time Scheduling의 다양한 기법 중에 Fixed-Priority 방식의 스케줄링 기법입니다. 즉, 사전에 각 task의 priority를 설정하고 이는 실행중에 변경되지 않습니다. 각 priority는 어떻게 설정하냐면, 실행 주기가 빠른 task에 높은 priority를 부여합니다. 이를 다른 말로 하면, 자주 실행되는 task1을 우선적으로 실행시키고 시간이 남으면 그 다음 자주 실행되는 task2를, 또 시간이 남으면 그 다음 자주 실행되는 task3를 실행시키는 방식입니다. 즉, 자주 실행된다 == 절대로 deadline miss가 일어나면 안된다는 전제를 가집니다. 자주 일어나는 task에 높은 우선순위를 부여해 deadline miss가 일어나지 않도록 합니다.
위의 공식에 대해서 설명드리기 전에 용어에 대해 짤막하게 설명드리면, U는 각 task의 Utilization(C/T)의 합, C는 각 task의 WCET (Worst-Case Execution Time), T는 각 task의 주기, m은 task의 개수를 의미합니다.
이를 바탕으로 저 공식을 설명드리면, 예를 들어 task의 개수 m=3 이라고 하면, U <= 78%라는 말이 되는데요, 즉 모든 task의 Utilization의 합이 78%이하가 되면 스케줄링이 일어날때 절대로 Deadline이 넘어가는 일이 일어나지 않는다는 것을 의미합니다. 즉, RM의 장점은 사전에 task의 개수를 알고 있으면 Utilization의 비율을 저 공식의 결과값 이하로 유지해 주면 절대로 Deadline miss가 일어나지 않는다는 것을 보장합니다.
RM은 멀티코어용은 아니고 싱글 코어, 좀 더 정확하게는 Local-Uniprocessor에 국한해서 사용됩니다.
아래 예시를 보면 이해가 좀 편할 것 같습니다.
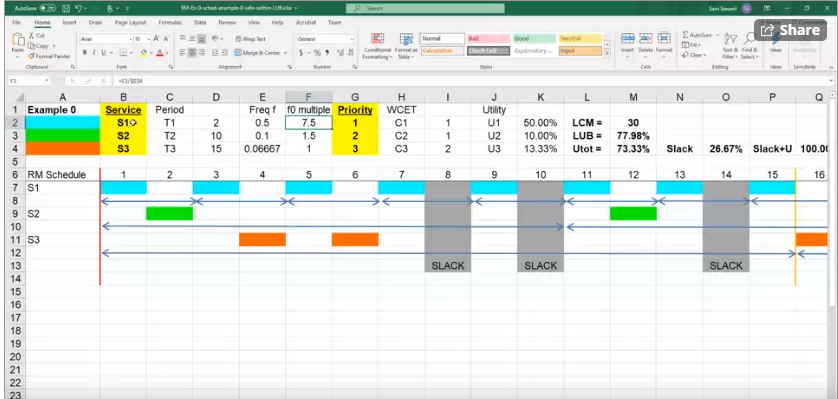
글로 풀어 보면, 각 task S1, S2, S3의 주기는 2, 10, 15라고 가정하고, 각각의 WCET(Worst-Case Execution Time)은 1, 1, 2라고 가정해 보겠습니다.
S1, S2, S3순으로 자주 실행되므로 S1에 가장 높은 우선순위(1), S2에 그다음(2), S3에 그 다음다음(3)을 줍니다.
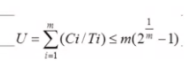
우선 scheduling diagram을 보기 전에 RM 공식에 값을 넣어서 계산을 해보겠습니다.
좌변:
각각 task의 Utilization (C/T)은 각각 1/2, 1/10, 2/15로 50%, 10%, 13.33%가 됩니다. 이 각각의 Utilization을 합해서 Sum을 구해보면 73.33%가 나옵니다.
우변:
task의 개수가 3개 이므로 m=3을 대입하면 LUB (Least Upper Bound)가 77.98%가 나옵니다.
73.33% < 77.98% 이므로 위와 같이 스케줄링을 구성할 경우 Deadline miss는 절대로 일어나지 않습니다.
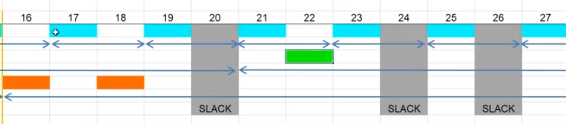
실제로도 그런지 scheduling diagram을 그려보면 위와 같은데요,
가장 우선순위가 높은 S1은 주기 2초마다 1번씩 규칙적으로 실행되는 것을 볼 수 있고,
그다음 순위인 S2는 10초 마다 S1이 다 실행하고 남는 시간에 한 번식 실행되는 것을 볼 수 있고
그 다음 순위인 S3는 15초 마다 S1, S2가 다 실행하고 남는 시간에 한 번식 실행되는 것을 볼 수 있습니다.
아무 task도 실행되지 않는 시간은 SLACK 타임이라고 하는데요, 보통 이 SLACK타임을 활용하여 다른 부수적인 task를 돌리기도 합니다.
궁금점: 만약에 각 task의 Utilization의 합이 RM Least Upper Bound를 넘어가면 어떻게 될까요. 이 경우에는 Deadline miss가 반드시 일어난다고도 안일어난다고도 할 수 없습니다. Deadline miss가 일어나는지는 tool을 이용해서 시뮬레이션을 해보던가 손으로 그려봐야 됩니다.

참조 : 시그널 리스트
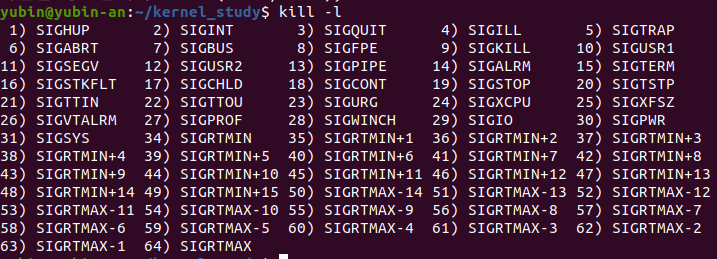
첨언 하면, 어떠한 문제가 발생한거에 대해 핸들러를 통해 전부제어가 되고
sigkill(9), sigstop(19)은 제어할수없습니다(핸들러를 작성해도)
Signal 번호는 아키텍처마다 달라서 확인해야 합니다.
ip stack 참고 자료
https://d2.naver.com/helloworld/47667
Superblock 과 inode
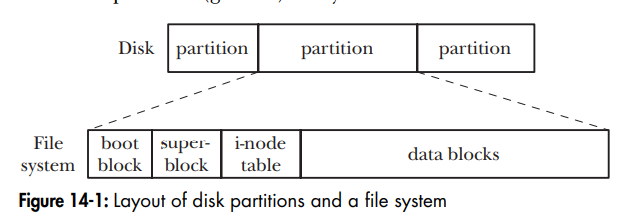
ExtX 슈퍼블록은 파일시스템 시작으로부터 1024바이트에 위치하고 크기가 1024 바이트이지만 실제로 사용하는 바이트 수는 적다. 이 데이터 구조체는 단지 설정 값들만 포함하고 있으며 부트코드는 포함하지 않는다. 슈퍼블록의 복사본은 보통 각 그룹의 첫 블록에 저장된다.
- 슈퍼블록에는 각 블록크기, 전체 블록수, 블록 그룹당 블록 개수, 첫 블록 그룹보다 전에 예약된 블록의 수와 같은 기본정보가 있다. 또한 inode 전체 개수와 블록 그룹당 inode 개수를 포함한다. 슈퍼블록의 부가 데이터로는 볼륨이름, 마지막 수정시간, 마지막 마운트 시간, 파일시스템이 마지막으로 마운트된 경로 같은 정보가 있다. 파일시스템이 깨끗한 상태인지, 무결성 검사가 실행될 필요가 있는지 식별하는 값 또한 포함한다. 슈퍼블록은 비사용중인 inode와 볼륨들의 전체 개수에 대한 데이터를 기록한다. 이것들은 새로운 inode와 블록들을 할당할 때 사용된다.
- 파일시스템 레이아웃을 결정하기 위해서 파일시스템 크기를 계산하는데 필요한 블록크기와 블록개수를 알아야한다. 이러한 값들이 볼륨 크기보다 작다면 파일시스템에 '볼륨슬랙' 공간이 있을 수 있다. 첫 번째 블록 그룹은 예약된 영역 다음 블록에 위치한다.

https://koromoon.blogspot.com/2018/05/inode-symbolic-link-hard-link.html
( 1 ) 아이노드(inode)
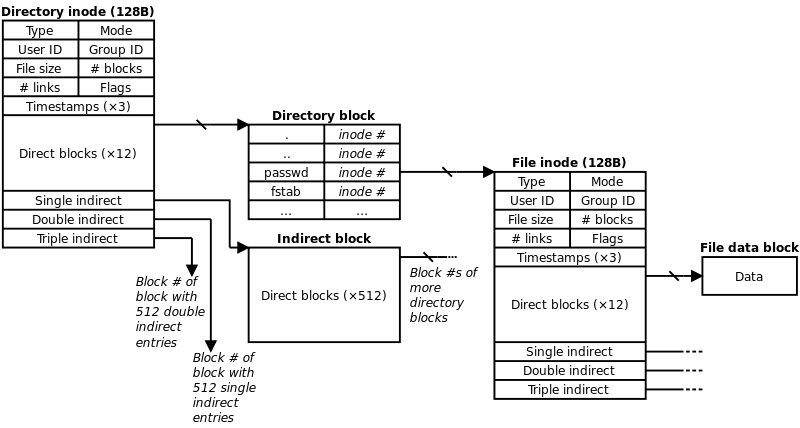
< 출처 - commons.wikimedia.org >
심볼릭 링크와 하드 링크를 이해하기 위해서는 inode 를 먼저 이해해야 함.
UFS 와 같은 전통적인 유닉스 계통 파일 시스템에서 사용하는 자료 구조임.
파일 시스템 내에서 파일이나 디렉토리는 고유한 inode 를 가지고 있으며 inode 번호를 통해 구분이 가능함.
사용자가 파일 또는 파일과 관련된 정보에 액세스하려고 하면 파일 이름을 사용하지만 내부적으로 파일 이름은 먼저 디렉토리 테이블에 저장된 inode 번호로 매핑됨.
그런 다음 해당 inode 번호를 통해 해당 inode 에 액세스 됨.
inode 에 포함된 정보는 아래와 같음.
- 파일 모드(퍼미션)
- 링크 수
- 소유자명
- 그룹명
- 파일 크기
- 파일 주소
- 마지막 접근 정보
- 마지막 수정 정보
- 아이노드 수정 정보
inode 포인터 구조를 통해 파일의 실제 데이터가 저장된 블록의 정보를 포함하여 파일의 메타 데이터 정보만 저장시킴.
대부분의 파일 시스템에서는 15개의 포인터로 된 데이터 구조가 저장되어 있으며 자세한 구조는 생략함.
2012년 12월에 Linux i386 arch 지원 멈춤 (커널 버전 3.8)
Ubuntu 지원 32bit x86 중단 : https://lwn.net/Articles/791509/
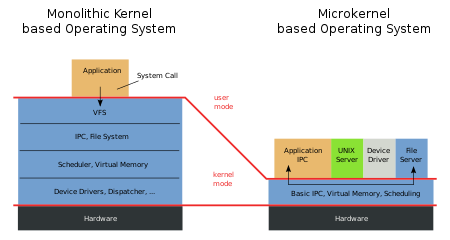
운영 체제의 구성요소를 단일의 메모리 공간에서 실행하는 모놀리식 커널에 대해, OS를 구성하는 몇 개의 요소, 기능을 커널 공간으로부터 떼어내어, 외부 모듈화하는 등으로 추가하는 기법을 마이크로 커널이라고 부른다. 모놀리식 커널의 설계 사상 및 개념 그 자체는 예전부터 존재했지만, 모놀리식 커널이라고 하는 용어가 성립된 것은, 마이크로 커널이라는 개념이 등장하면서 그 반대 개념으로서 명명되었다.
리눅스 커널의 경우 모듈(디바이스 드라이버 등)을 런타임에 로드할 수 있어 마이크로 커널의 장점을 가지고 있고 hybrid kernel 이라고도 부른다.
중요한 내용은 아니지만 26pg. 에서 나온 두 용어: IEEE, POSIX 는 발음이 따로 정해져 있습니다.
IEEE 는 아이-이이이가 아닌 아이 트리플 이로 발음하는 것이 맞습니다.
IEEE, pronounced "Eye-triple-E," stands for the Institute of Electrical and Electronics Engineers. The association is chartered under this name and it is the full legal name.
POSIX 는 포식스가 아닌 파직스로 발음하는 것이 맞습니다. 포식스는 46 로 오해할 여지가 있기에 파직스로 발음합니다. 그에 대한 출처는 아래와 같습니다: http://www.opengroup.org/austin/papers/posix_faq.html
RoCE 인피니밴드(infiniband)
https://blog.daum.net/wirelessall/1910
18차 스터디는 arm64 기준으로 분석을 하지만 arm도 호환되므로 아키텍처는 우선 32bit로 공부하고 소스코드는 64bit 기준으로 공부.

-
Piggy.o란?
|
piggy.gz |
The file Image compressed with gzip. |
|
piggy.o |
The file piggy.gz in assembly language format so it can be linked with a subsequent object, misc.o (see the text). |
|
misc.o |
Routines used for decompressing the kernel image (piggy.gz), and the source of the familiar boot message: "Uncompressing Linux … Done" on some architectures. |
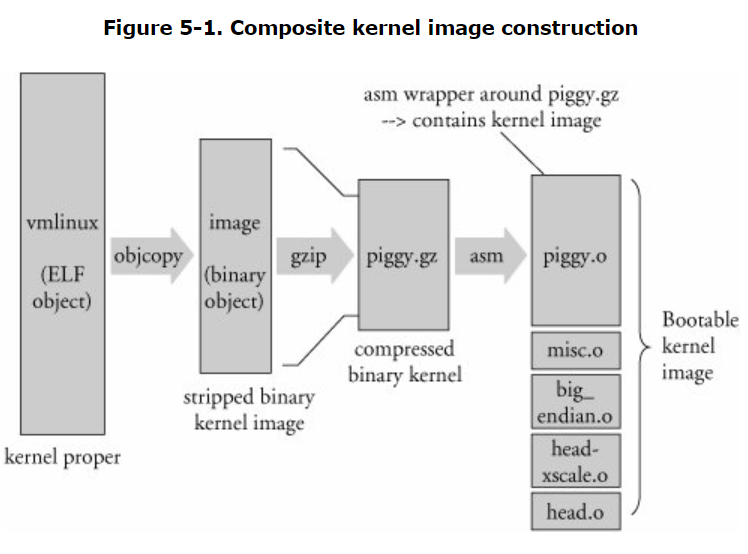
http://www.embeddedlinux.org.cn/EmbeddedLinuxPrimer/0136130550/ch05lev1sec1.html#ch05fn02
vmlinux에서 불필요한 section을 날린것이 image
image의 용량을 줄이기 위해 압축한 것이 piggy.gz (요즘에는 gz외의 압축 알고리즘도 지원하여 piggy_data라고도 불림)
piggy.S (image를 실행하기 위한 부트스트랩 코드) 과 piggy.gz를 합쳐서 piggy.o를 생성한다
https://www.programmersought.com/article/11921096522/
-
objcopy단계 (vmlinux -> image) 에서 재배치(relocation)정보는 왜 삭제할까?
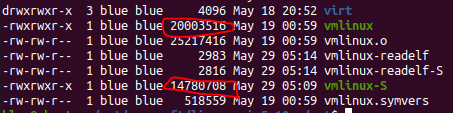
objcopy -S 한 후 용량이 많이 줄음 (위 -> 아래)
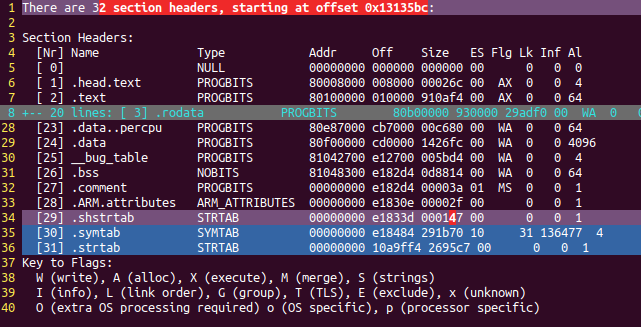
readelf를 통해 vmlinux의 section header의 차이를 보면
위:
아래 (objcopy -S 후):
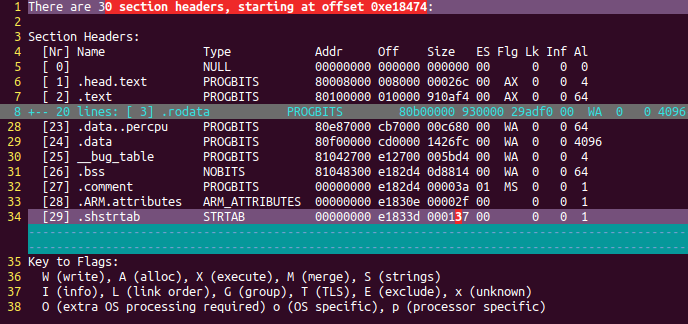
.symtab : 이 파일에 포함되는 심볼 표. 실제로는 .strtab 섹션에 저장됨
.strtab : 심볼 등의 문자열 테이블
.shstrtab : 섹션명의 문자열 테이블
vmlinux.lds -> 링커스크립트 파일
ab.o 어떤함수는 X section
어떤함수는 Y section
df.o
디폴트로는 보통 .text, .rodata, .data, .bss 등등의 섹션으로 들어감
커널은 relocate를 왜할까?
ex) .init섹션 같은 경우 부팅 후에 지움 (한번 init하면 나중에 불필요)
크기, 성능, 보안, 권한 등등의 이유
-
ELF 파일 형식이란?
ELF(Executable and Linkable Format)는 실행 파일, 목적 파일, 공유 라이브러리 그리고 코어 덤프를 위한 표준 파일 형식이다. 1999년 86open 프로젝트에 의해 x86 기반 유닉스, 유닉스 계열 시스템들의 표준 바이너리 파일 형식으로 선택되었다.

-
Copy-on-Write :
-
Linux(Unix)에서는 자식 프로세스(child process)를 생성(fork)하면 같은 메모리 공간을 공유하게 된다. 그런데 부모 프로세스가 데이터를 새로 넣거나, 수정하거나, 지우게 되면 같은 메모리 공간을 공유할 수 없게 된다. 이때 부모 프로세스는 해당 페이지를 복사한 다음 수정한다. 이것을 Copy-on-Write(COW)라고 한다.
-
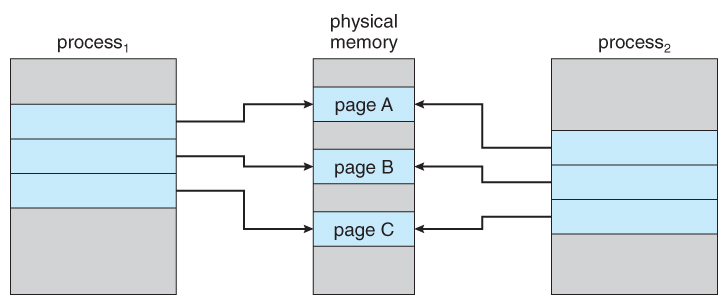
Figure 9.7 - Before process 1 modifies page C.
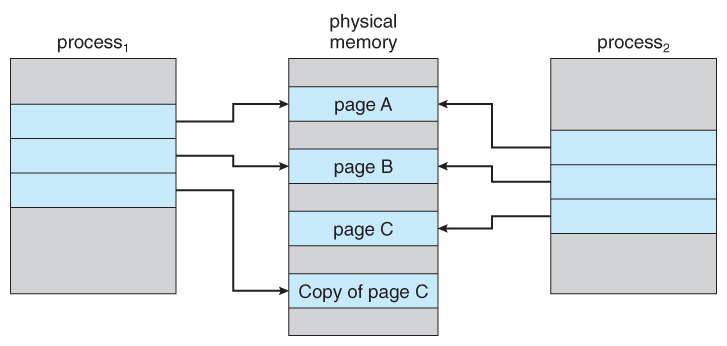
Figure 9.8 - After process 1 modifies page C.
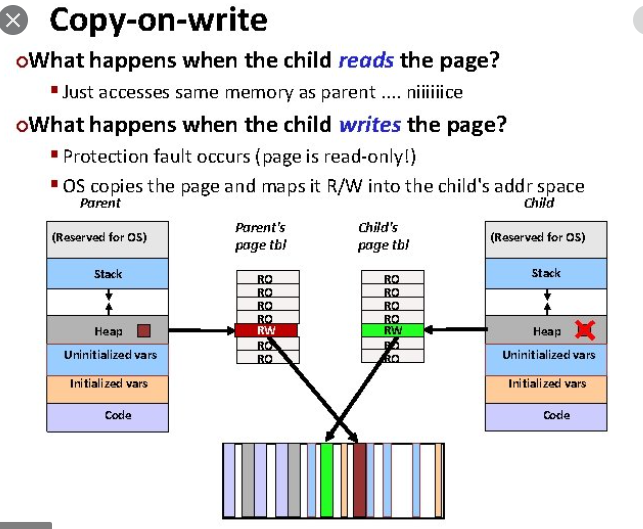
Read-Only에 Write를 하는 순간 Protection fault 가 발생하면 그제서야 새로운 메모리 영역 확보 및 복사
heap의 경우는 어떨까?
glibc의 brk()함수 -> VMA(Virtual Memory Address)에 공간만 잡아둠 (시작, 끝, 사이즈)
Write를 하는 순간 실제 메모리를 확보
-
PID vs TGID (헷갈림 주의)
PID(Process IDentifier)
TGID(Thread Group Identifier)
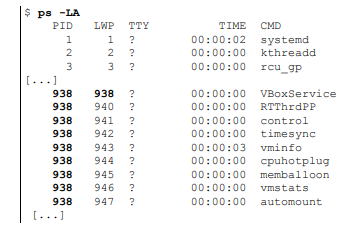
여기서 PID는 TGID를, LWP(Light Weight Process, or Thread)는 PID를 나타낸다.
tgid는 'task_struct→tgid'. 이를 출력하는 유저 함수는 getpid() , 커널 함수는 task_tgid_nr()
pid는 'task_struct→pid'. 이를 출력하는 유저 함수는 gettid(), 커널 함수는 task_pid_nr()
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 공지 | [공지] 스터디 정리 노트 공간입니다. | woos | 2016.05.14 | 626 |
| 68 | [커널 17차] 41주차 | ㅇㅇㅇ | 2021.06.13 | 36544 |
| 67 | [커널 18차] 3주차 | V4bel | 2021.06.12 | 103 |
| 66 | [커널 17차] 40주차 | ㅇㅇㅇ | 2021.06.05 | 283 |
| 65 | [커널 18차] 2주차 | V4bel | 2021.06.05 | 271 |
| 64 | [커널 17차] 39주차 | ㅇㅇㅇ | 2021.05.29 | 183 |
| » | [커널 18차] 1주차 | V4bel | 2021.05.29 | 3599 |
| 62 | [커널 17차] 38주차 | ㅇㅇㅇ | 2021.05.23 | 366 |
| 61 | [커널 17차] 37주차 | ㅇㅇㅇ | 2021.05.16 | 97 |
| 60 | [커널 17차] 36주차 [2] | ㅇㅇㅇ | 2021.05.09 | 133 |
| 59 | [커널 17차] 35주차 | ㅇㅇㅇ | 2021.05.05 | 85 |
| 58 | [커널 17차] 34주차 | ㅇㅇㅇ | 2021.04.25 | 99 |
| 57 | [커널 17차] 33주차 | ㅇㅇㅇ | 2021.04.18 | 195 |
| 56 | [커널 17차] 32주차 | ㅇㅇㅇ | 2021.04.11 | 443 |
| 55 | [커널 17차] 31주차 [2] | ㅇㅇㅇ | 2021.04.04 | 158 |
| 54 | [커널 17차] 30주차 [1] | 주영 | 2021.03.30 | 203 |
| 53 | [커널 17차] 29주차 | ㅇㅇㅇ | 2021.03.26 | 103 |
| 52 | [커널 17차] 27주차 | 주영 | 2021.03.15 | 276 |
| 51 | [커널 17차] 27주차 | 주영 | 2021.03.08 | 172 |
| 50 | [커널 17차] 26주차 | 주영 | 2021.03.01 | 539 |
| 49 | [커널 17차] 25주차 | 주영 | 2021.02.23 | 91 |
.
