
안녕하세요.
현재 라즈베리파이 3 ethernet 드라이버에 accelerator 관련 기능을 넣는 개인 프로젝트를 하고 있습니다. 아래 그림과 같은 아키텍처로 설계한 다음 돌아가는 건 확인했는데 문제는 softirq와 일반 task context 간의 데이터 동기화가 제대로 이루어지는지 검증을 해보고 싶습니다. 어떠한 방식으로 하면 좋을지 조언 부탁드립니다.
* workq는 워크큐를 의미합니다.
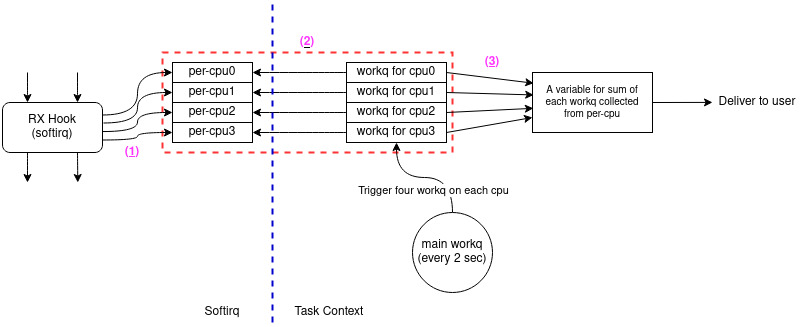
(1) 에서는 rx hook에서 가져온 데이터를 per-cpu 변수에다가 담습니다. 이때는 softirq 처리 도중이므로 아무런 lock도 사용하지 않습니다. (irq가 disable이고 non-preemptiable kernel이라 가정했습니다)
(2)가 critical section인데 main workq에서 생성된 4개의 per-cpu 처리용 workq는 irq을 disable하고 per-cpu 데이터를 빠르게 복사한다음 각 per-cpu 변수를 0으로 초기화합니다. 그리곤 irq을 다시 enable 합니다.
(3)에서는 spinlock 이용해 sum이란 하나의 변수에 4개의 per-cpu 데이터를 합칩니다.
제가 알고 싶은 부분은 다음과 같습니다.
1. 임계영역에서 데이터 동기화가 제대로 이루어지는 검증할 수 있는 방법
2. 위와 같이 설계할 때 주의해야 될 부분 (예, irq, rcu lock 등등)
추가로 프로젝트 링크도 첨부드리니 혹시 시간되시면 보시고 문제가 될 부분이나 검증 방법에 대해 조언해주시면 감사드립니다!
댓글 7
-
mnth
2021.01.09 14:08
-
DEWH
2021.01.09 18:30
정확히 "데이터 동기화"라는 용어를 어떤 의미에서 사용했는지 잘 모르겠습니다.
collect_stat_start이 실행시작될 때 순간의 percpu의 데이터를 정확히 읽어오는 것을 의미하시는건가요?
-
mnth
2021.01.09 22:38
네 그렇습니다.
해당 함수 진입 후 local_irq_disable 이전에 irq 요청이 들어와 핸들링하게 되면 어떤 플로우로 처리되는지 예상이 잘 안되는 것 같습니다.
-
DEWH
2021.01.10 00:40
전문가는 아니지만 제 의견을 드리자면..
local_irq_disable하기 전에 irq가 들어온다면,
collect_pcpu_stat_cb()
... ---------interupt------> percpu write
local_irq_disable()
percpu read
percpu write
local_irq_disable()
위와 같이 percpu 데이터가 갱신될 것 같네요. 그런 다음 갱신된 값을 global 카운터에 더합니다.
만약 local counter를 global counter로 합치는 일이 목적이라면 몇 가지 의문사항이 있습니다.
1) 굳이 local counter를 다시 0으로 세팅해야하는가?
만약 local counter에 write하지 않는다면, local_irq_disable()은 필요없어 보입니다.
2) for_each_possible_cpu(i)에서 smp_call_on_cpu를 사용하는 특별한 이유가 있는가?
해당 함수에서 per_cpu_ptr(ptr, cpu)으로 각 cpu의 local counter에 접근해도 문제없긴 합니다.
-
mnth
2021.01.11 21:01
답변 감사합니다!
질문 주신 내용으로 보아 코드를 보신듯하여 자잘한 내용은 빼겠습니다.
2) 현재 코드가 per-cpu에서 읽은 뒤 해당 변수를 0으로 초기화하도록 되어 있는데 smp_call_on_cpu를 사용하지 않으면 동기화 이슈가 생길 것이라 판단하였습니다. 예를 들어 for_each_possible_cpu를 실행하는 context는 cpu4인데 cpu0의 per-cpu 데이터를 읽고 "쓰기(0으로 reset 하는 코드)"를 수행해야 하기 때문입니다. 그래서 cpu마다 workq를 할당하도록 해당 함수를 이용하였습니다.
답변 해주신 내용을 읽고 곰곰히 생각해보니 패킷 통계값은 계속 per-cpu 변수에 저장해놓고 user가 proc 파일을 read할 때 per_cpu_ptr로 접근해 읽은 뒤 sum 하여 리턴하는 것이 더 효율적이라 생각되어 해당 방법으로 수정할 예정입니다 ㅎ 이와 별개로 추가 기능을 넣을 계획이 있는데 그 기능은 아마 저 방식을 써야하지 않을까 싶습니다.
-
DEWH
2021.01.12 10:38
>답변 해주신 내용을 읽고 곰곰히 생각해보니 패킷 통계값은 계속 per-cpu 변수에 저장해놓고 user가 proc 파일을 read할 때 per_cpu_ptr로 접근해 읽은 뒤 sum 하여 리턴하는 것이 더 효율적이라 생각되어 해당 방법으로 수정할 예정입니다
이제 해당 방식의 문제는, 빈번하게 read가 발생할 때, 성능저하가 발생할 수 있는데 precision과 trade off할 수 있습니다.
리눅스에서 Counter를 사용하는 방식을 살펴보는 것도 도움이 될 것 같습니다.
http://jake.dothome.co.kr/zonned-allocator-watermark
위 링크의 "존 카운터(stat)" 키워드는 vm에서의 통계 값 처리하는 방식을 설명하고 있습니다.
또는 perfbook 책을 살펴보는 것도 도움이 됩니다.
-
mnth
2021.01.13 00:41
perfbook 내용 너무 좋네요. 제가 궁금해 하던 것들 실마리가 대부분 들어 있는거 같습니다. 링크와 책 추천 고맙습니다!
.

(2)에 대해 추가로 고민해본 것이 있는데 예를 들어 cpu0 이 per-cpu0 데이터 처리를 위해 cpu0 workq callback을 호출하고 irq_disable 이전에 irq가 발생하여 softirq가 우선처리되면 데이터 동기화가 실패하지 않을까 생각되네요... 요건 조금 긴가민가합니다...
프로젝트 코드는 이 부분입니다. --> https://github.com/net-rw/smsc95xx-drv/blob/b14ae568749043e7300a9452e9f41b7600781028/smsc-netrw.c#L142