
안녕하세요. C조 23주차 스터디를 진행하는 중, 궁금한점이 생겨 질문 드립니다.
start_kernel()
setup_arch()
setup_machine_fdt() 시작 지점
fixmap_remap_fdt()
__fixmap_remap_fdt()
__fix_to_virt()
create_mapping_noalloc()
__create_pgd_mapping()
__create_pgd_mapping()
질문 1.
init/main.c : start_kernel()
~ arm64/kernel/setup.c : setup_arch()
~ arm64/mm/mmu.c : early_fixmap_init()
~ arm64/kernel/setup.c : setup_machine_fdt()
~ arm64/mm/mmu.c : fixmap_remap_fdt()
→ 앞서, setup_arch에서 이미 fixmap을 만들었는데, 왜 remapping이 필요할까요?
질문 2.
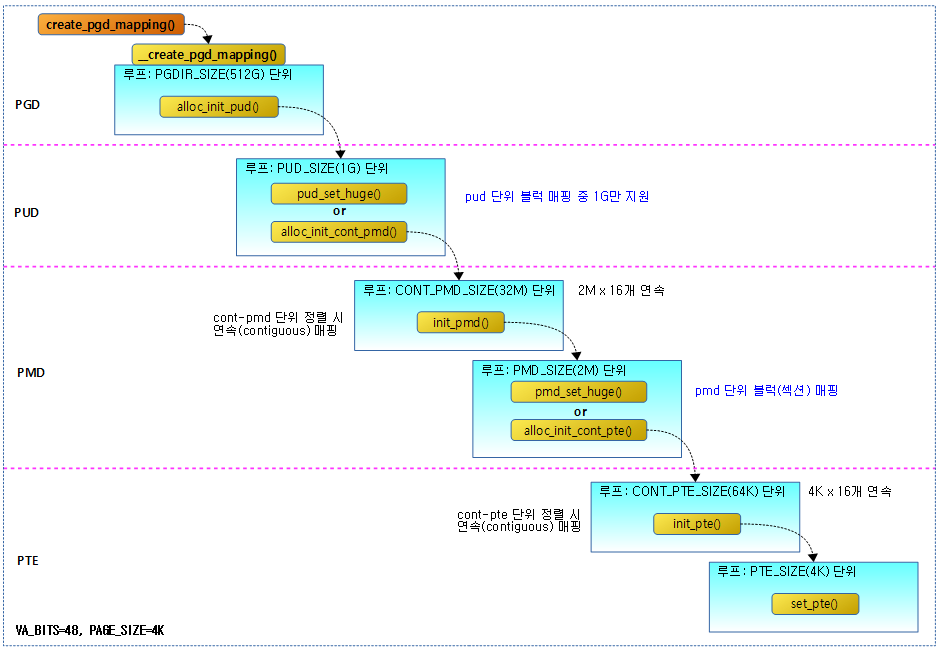
alloc_init_pud() 에서
use_1G_block(addr, next, phys) && (flags & NO_BLOCK_MAPPINGS) == 0
→ True:
pud_set_huge()
False:
alloc_init_cont_pmd()
init_pmd() 에서
(((addr | next | phys) & ~SECTION_MASK) == 0) && (flags & NO_BLOCK_MAPPINGS) == 0
→ True:
pmd_set_huge()
False:
alloc_init_cont_pte()
pmd_set_huge() , pud_set_huge() 각각의 함수가 어느 상황에 사용되는지 궁금합니다.
감사합니다.
.

안녕하세요? 문c블로그(http://jake.dothome.co.kr)의 문영일입니다.
질문 1. 앞서, setup_arch에서 이미 fixmap을 만들었는데, 왜 remapping이 필요할까요?
-> head.S에서 mmu가 꺼진 상태에서 fdt에 접근한 적이 있습니다. 그 후 mmu가 켜진 후
start_kernel()로 넘어오면 다시 fdt에 접근할 수 없는 상태가 됩니다. 아키텍처별 고유의
설정을 위해 동작하는 setup_arch()로 이동해오면 서둘러 fdt에 접근하여야 합니다.
왜냐면 아키텍처별로 급하게 설정해야 할 값들이 fdt에 있기 때문이겠죠? 그래서 아직
매핑되지 않은 fdt의 접근을 위해 매핑을 시도합니다.
mmu가 켜진 상태에서 cpu는 항상 가상 주소로 access를 하겠죠?
fixmap이란 것은 고정(fix)된 가상 주소 영역을 사용해서 물리 주소를 매핑하고 이의 영역에
접근하는 방법에 사용되는 즉 고정된 가상 주소 영역을 사용하는 매핑방법입니다.
fixmap을 만들었다는 것은 그러한 기반만을 준비하였다는 것이고, early_fixmap_init()
함수에서 실제로 fdt를 매핑한 적이 없습니다. 아직 fdt의 영역에 접근할 방법이 없는
상태입니다. 따라서 setup_machine_fdt() 함수안에서 fixmap_remap_fdt() 함수를 호출하여
fdt 물리 영역을 readonly로 fixmap에 매핑하여 사용할 수 있게 하였습니다.
(2번 매핑한게 아니죠? 물론 CONFIG_RANDOMIZE_BASE(디폴트=n) 커널 옵션을 사용한 경우
MMU를 켜서 fdt 영역을 먼저 매핑하므로 setup_arch()에서 호출된 경우에는
리매핑된 것이기도 합니다. 가상 주소만 동일하면 두 번, 세 번 매핑되어도 가장 마지막에
매핑한 속성만 유효합니다. 커널의 매핑 함수가 가끔 remap이라는 용어를 사용하는데
처음 매핑이든 두 번째 매핑이든 remap이라는 용어를 쓰는게 습관(?)화 되었습니다.)
질문 2. pmd_set_huge() , pud_set_huge() 각각의 함수가 어느 상황에 사용되는지 궁금합니다.
-> 페이지 (디폴트: 4K) 범위의 물리 주소 공간을 가상 주소 공간으로 변환하는데 가장 마지막
레벨의 PTE 테이블에서 1 개의 엔트리로 소요됩니다. 이는 TLB 캐시에 저장될 때 1개의
엔트리를 소모합니다. access하는 물리 주소 공간이 연속되어 있다는 보장이 있는 경우
ARM64 아키텍처는 2M 단위 align된 물리 주소 공간을 PMD 테이블에서 1개의 엔트리로 만들
수도 있고, 1G 단위 align된 물리 주소 공간을 PUD 테이블에서 1개의 엔트리로 만들 수도
있습니다. 이렇게 큰(huge) 공간으로 매핑할 수 있는 방법은 TLB 엔트리 소모를 혁신적으로
줄여줍니다. 이는 TLB 캐시의 성능이 그 만큼 크게 개선되는 것과 동일합니다.
감사합니다.